自宅では長らくフレッツ + YBB を用い、 YBB 支給の光BBユニットによる v4 over v6 でインターネットに接続してきたが、色々面倒なので長らく IPv6 はルーターで遮断し、 IPv4 のみで使っていた。今回、サーバがいるネットワークは一旦除くとして、 PC や携帯電話といったクライアントがいるネットワークについては IPv6 も使えるようにすることにした。
ひかり電話は契約していないので、 IPv6 は /64 のネットワークが一つだけ利用できる。そのため、これ以上ネットワークを分割することはできないので、インターネット接続が可能な IPv6 ネットワークは、全てブリッジ(嘘)で接続する必要がある。しかし、現在 IPv6 でサーバーは立てていないはずではあるものの、一応 LAN の中にあるようなサーバーには、明示的に開けたもの以外は NGN から直接接続できないようにしておきたい。
現在ルーターとしては、YANLING IBOX-501 N13 の Celeron 3855U モデル に Ubuntu 20.04 を入れて利用している。なお、購入履歴を見ると2020年7月に $151.38 で買っているが、今見るとこれ自体はもう購入できないようだ。既にここに繋がっているネットワークに対し、 ONU から IPv6 ネットワークを引くことにする。
なお、光BBユニットではなく ONU 側から Ubuntu ルーターにケーブルを引いたので、光BBユニット特有の事情はここでは登場しない。ただし、 YBB 特有の事情が完全に絡んでいないかどうかはわからない。
Open vSwitch でブリッジ(嘘)を構成する
L2 ブリッジ(嘘)を Open vSwitch で構成する。
まずは
apt install openvswitch-switch
しておく。
(書き忘れていたので追記)今回の構成で、 openvswitch を restart したときに、 bridge と port が残って flow だけ消えて L2 ブリッジ(本当)として動作する状態に戻ってしまい、そのままではセキュリティ上問題がありそうだった。とりあえず、 restart 時に bridge を削除する設定はあったので、これを入れた。
$ grep OVS_CTL_OPTS /etc/default/openvswitch-switch
# OVS_CTL_OPTS: Extra options to pass to ovs-ctl. This is, for example,
OVS_CTL_OPTS=--delete_bridges=yes
netplan の yaml でブリッジを追加する。br_flets には ONU にブリッジ(本当)で繋がるように設定し、 br_homelan はもとから自宅のネットワークとして使っていたものを想定している。(br_homelan はもとからあったもので、 IPv4 とデュアルスタックのため、 IPv4 の設定が書かれている。)
network:
bridge:
...
br_homelan:
interfaces:
- enpXXXXX
addresses:
- 192.168.XXX.XXX/24
dhcp6: false
accept-ra: false
link-local: []
nameservers: {}
br_flets:
interfaces:
- enpXXX
accept-ra: false
Open vSwitch で br_flets から br_homelan に IPv6 を、基本的には中から外への通信を許可して最低限の ICMPv6 通信を許可する想定で書いてみる。ただし、これは最終的なスクリプトからこの時点で必要なものを抜粋したもの。なお、このスクリプトを書くには ovs-actions(7) – Linux manual page を参照したが、 table は 0 のままにしてある。
#!/bin/bash -eux
ovs-vsctl --may-exist add-br flets_v6
ovs-ofctl add-flow flets_v6 cookie=0x100000001,priority=10,action=drop
ip link add veth_flets_br type veth peer name veth_flets_ovs || true
ip link set veth_flets_br master br_flets
ovs-vsctl --may-exist add-port flets_v6 veth_flets_ovs
ip link add veth_homel_br type veth peer name veth_homel_ovs || true
ip link set veth_homel_br master br_homelan
ovs-vsctl --may-exist add-port flets_v6 veth_homel_ovs
ovs-ofctl del-flows flets_v6 cookie=0x100000002/-1
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=320,ipv6,ct_state=+trk+est,action=normal
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=310,ipv6,ct_state=-trk,action="ct(table=0)"
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=310,ipv6,ct_state=+trk+new,in_port=veth_flets_ovs,action=drop
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=300,ipv6,ct_state=+trk+new,in_port=veth_homel_ovs,action="ct(commit),normal"
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=100,ipv6,icmp6,icmp_type=1,action=normal
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=100,ipv6,icmp6,icmp_type=2,action=normal
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=100,ipv6,icmp6,icmp_type=3,action=normal
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=100,ipv6,icmp6,icmp_type=4,action=normal
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=100,ipv6,icmp6,icmp_type=133,action=normal
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=100,ipv6,icmp6,icmp_type=134,action=normal
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=100,ipv6,icmp6,icmp_type=135,action=normal
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=100,ipv6,icmp6,icmp_type=136,action=normal
ip link set veth_flets_br up
ip link set veth_flets_ovs up
ip link set veth_homel_br up
ip link set veth_homel_ovs up
Open vSwitch と ConnTrack を連携させることにより、基本的に中から外の通信でのみ established 扱いとして通信できるようにしているが、 RA 含め、いくつか通信やアドレス設定に必須と考えられる項目を追加している。この辺りは精査が必要かもしれない、
なお、この後も含め、 priority の指定を昔の BASIC の行番号みたいな感じにしているが、削除して整理できるので一応連番でつけても支障がないはずではある。
LAN 内 DNS サーバー(Unbound)を IPv6 で待ち受ける
基本的には LISTEN はさせるだけではあるが、今回だと IPv6 アドレスは可変で、自分で決定できないという問題がある。そのため、
- unbound の設定ファイルには、 LISTEN するインターフェイス名の指定はIPアドレス指定はあったが、インターフェイス名指定が見当たらなかった
- 仮に DNS 自体の LISTEN がうまくいったとしても、それを LAN 内に広報する必要がある
という問題がある。設定ファイルの動的生成はできればやりたくないので、 unique local address (Unique local address – Wikipedia)で LISTEN させて、 LAN 内からのみ到達できるようにする。
なお unique local address はインターネットに流すことができないIPアドレスで、 fd00::/8 のレンジのものだが、どうやら RFC4193 ではなぜか、 fd に続く40ビット(Global ID)を RANDOM な値にするようになっており、 sequentially に割り当てたり well-known な数字を使うことはなぜか MUST NOT になっているようだ。ローカルに閉じている以上 Global ID は自分で管理できていれば支障はない想定だが、真面目にやるなら40ビットの乱数を生成して fd の後に結合することでIPアドレスの先頭48ビットを決定することが望ましいかもしれない。
というわけで netplan の yaml を編集してこのアドレスを持つブリッジを作る。Open vSwitch 経由でしか受け付けないので子は netplan の時点ではいない。また、戻りのパケットを通すため、普通の方法で RA しているブリッジも用意する。
network:
bridge:
...
br_my_v6:
interfaces: []
accept-ra: true
br_v6dns_l:
interfaces: []
accept-ra: false
addresses:
- fdXX:XXXX:XXXX:1::1/64
Unbound はこの方法なら普通に LISTEN を追加できる。
interface: fdXX:XXXX:XXXX:1::1
access-control: 2400::/8 allow
Open vSwitch でいい感じにリクエストのパケットを誘導する。レスポンスは br_my_v6 の方から出ていくので action:normal にしておけば勝手に帰る。
#!/bin/bash -eux
ip link add veth_my_v6_br type veth peer name veth_my_v6_ovs || true
ip link set veth_my_v6_br master br_my_v6
ovs-vsctl --may-exist add-port flets_v6 veth_my_v6_ovs
ip link add veth_v6dns_br type veth peer name veth_v6dns_ovs || true
ip link set dev veth_v6dns_br address 0e:00:01:00:00:01
ip link set veth_v6dns_br master br_v6dns_l
ovs-vsctl --may-exist add-port flets_v6 veth_v6dns_ovs
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=410,ipv6,ct_state=+trk,in_port=veth_homel_ovs,ipv6_dst=fdXX:XXXX:XXXX:1::1,action=mod_dl_dst:0e:00:01:00:00:01,output:veth_v6dns_ovs
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=410,ipv6,ct_state=+trk,in_port=veth_my_v6_ovs,ipv6_dst=fdXX:XXXX:XXXX:1::1,action=mod_dl_dst:0e:00:01:00:00:01,output:veth_v6dns_ovs
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=400,ipv6,ct_state=+trk,ipv6_dst=fdXX:XXXX:XXXX:1::/64,action=drop
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=300,ipv6,ct_state=+trk+new,in_port=veth_my_v6_ovs,action="ct(commit),normal"
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=300,ipv6,ct_state=+trk+new,in_port=veth_v6dns_ovs,action="ct(commit),normal"
DHCPv6 をいい感じにして DNS サーバーを広報する
ここまでの時点で、 RA と別に DHCPv6 が降ってきてはいたのだが、クライアントに到達していなかった(Android ではそもそも DHCPv6 リクエストが行われなかった)。おそらく、行きがマルチキャストで帰りが src もユニキャストだった影響で、 ConnTrack で行きと帰りが別々の接続とみなされたからだと思う。幸いにして少なくとも現時点では RA には DNS サーバーの情報は含まれず、 IPv4 で使っていた DNS サーバーがそのまま使われているようだ。LAN 内の DNS サーバーでないと LAN 内のサーバーの IP アドレスがわからないのでそれ自体は望ましくはあるが、整理しておくのと、一応 IPv6 シングルスタックでも DNS が通るようにしておく。
なお、次のような DHCPv6 の情報が降ってきていた。軽くウェブ検索した限りだと、フレッツではまあまあ使われているサーバーのようには見える。
(DNS-server 2404:1a8:7f01:b::3 2404:1a8:7f01:a::3) (DNS-search-list flets-east.jp. iptvf.jp.)
現時点で、 RA は正しく到達し、 DHCPv6 を使用するようなフラグがセットされているようだ(次の出力は tcpdump を br_flets 側で取得し、 tcpdump で -tnlvv に相当するオプションもつけたもの)。
hop limit 64, Flags [other stateful], pref medium, router lifetime 1800s, reachable time 300000ms, retrans timer 10000ms
そして、 DHCPv6 の問い合わせも(行うよう実装・構成されている OS では)行われるが、結果パケットが弾かれて到達しないので使用できない。DHCPv6 は RA の送出元に送るわけではないようで、再度マルチキャストで行われるようだ。
なので、自前で DHCPv6 を受け付けて DNS サーバーだけを正しく返すことにする。
Linux の Network Namespace と radvd / dnsmasq で IPv6 SLAAC (+RDNSS) を試す – CUBE SUGAR CONTAINERの「dnsmasq (RA + Stateless DHCPv6)」では、 dnsmasq で RA と stateless DHCPv6 の両方を行っている。ただし、今回は dnsmasq はこの /64 ネットワークの実際のゲートウェイとは別のマシンで動かすので、 RA を行ってしまうと疎通しなくなる。dhcp-range=:: についての説明を man dnsmasq で読んでみても、 DHCPv6 を活かしながら RA を無効にする方法は見つけられなかった(見落としただけであるかもしれないが)。なので、この方法をベースに、 dnsmasq からの RA は Open vSwitch で叩き落すことにする。
#!/bin/bash -eux
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=420,ipv6,ct_state=+trk,in_port=veth_my_v6_ovs,icmp6,icmp_type=134,action=drop
ovs-ofctl add-flow flets_v6 cookie=0x100000002,priority=420,ipv6,ct_state=+trk,in_port=veth_flets_ovs,icmp6,tp_src=547,action=drop
ついでに、 flets 側からの DHCPv6 は叩き落しておくことにした。
dnsmasq 設定ファイル
interface=br_my_v6 # 既に listen-address がいても追記可能だった
dhcp-range=::,constructor:br_my_v6,ra-stateless
dhcp-option=option6:dns-server,[fdXX:XXXX:XXXX:1::1]
ただし、この方法では、将来フレッツが RA に RDNSS を付すようにしたときには、宅内の DNS サーバーでないと参照できない接続先へのアクセスでは困りそうだ。
IPv6 テストサイトの結果
The KAME project のウェブページでは、無事に踊っている亀を見ることができた。
https://ipv6-test.com/ では、次のようになった。
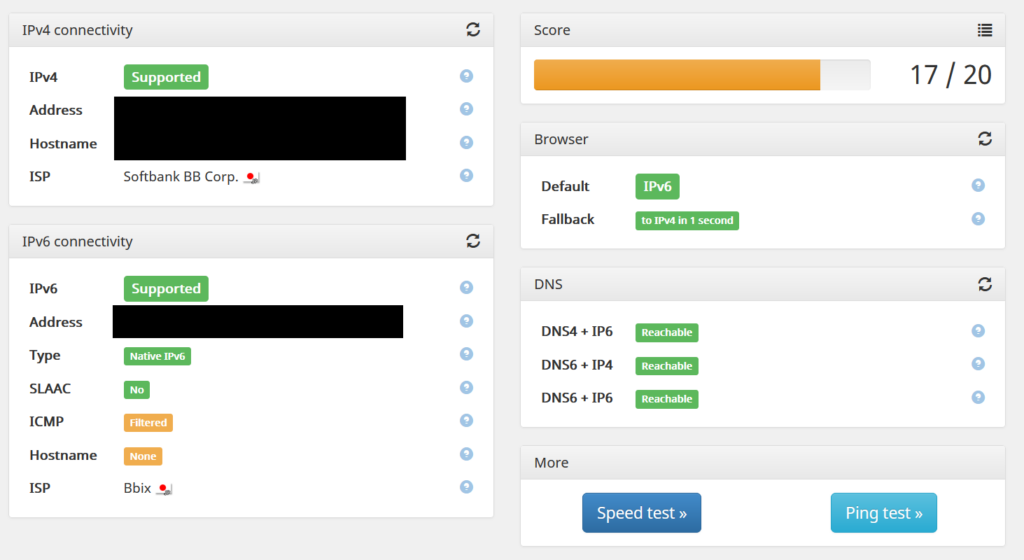
簡易速度測定
Ubuntu 21.04 のラップトップで、 IPv4 を無効にして IPv6 のみで今回で構成したネットワークに接続したところ、正しく DNS も解決され、 https://www.google.co.jp/ や https://nhiroki.net/ などの IPv6 接続が可能なウェブページには接続できた。また、その環境で、 Google 検索で “speedtest” と検索して出てきた Google 組み込み(Measurement Lab と提携とのこと)のスピードテストでは、次のような結果になった。
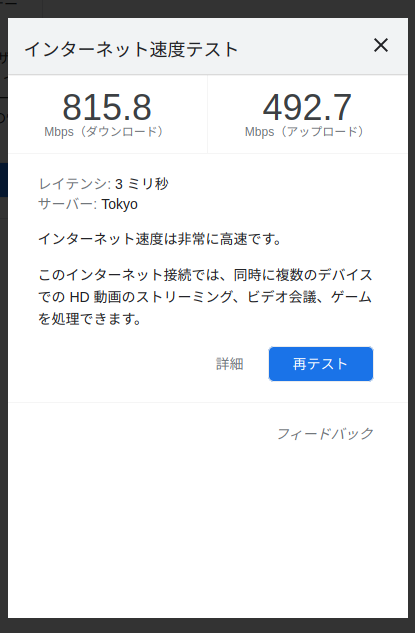
なので、ギガビットのインターネットの想定であれば、 Celeron 3855U + Ubuntu + Open vSwitch で IPv6 のブリッジ(嘘)を実現するのは、性能上は妥当だと言えそうだ。